1 留存分析概述
留存分析是一种用来衡量用户参与情况、活跃程度的分析模型,对进行初始行为后的用户进行观察,有多少人会进行后续行为。是衡量产品对用户价值高低的重要指标。
留存分析可以帮助回答以下问题:
● 一个新用户在未来的一段时间内是否完成了您期许用户完成的行为?如上传视频
● 某个社交产品新增了一种3D互动特效,期待改善用户之间的互动的频次,如何验证?
● 想判断某项产品改动是否奏效,如新增了一个推荐可能认识的好友功能,观察是否有人因快速找到好友,与好友在产品中形成互动而多使用产品几个月?
2 选择数据来源

在数据来源下拉框选择需要分析的数据集以及用户ID标识。默认以uin作为用户ID的标识。
3 选择初始行为及后续行为

初始行为:首先被触发的事件,用于筛选留存分析的原始人数。
后续行为:触发初始行为的人,在当天或以后一段时间要触发的事件。
初始行为和后续行为的两种选择策略:
1.初始行为和后续行为选择不同的。初始行为选择正常使用周期内,只触发一次的事件,比如“注册”、“登录”等,后续行为选择核心路径中,被用户重复触发的事件,比如“视频点赞”、“上传视频”等。这种留存分析也是最常用的,用于对比分析不同阶段开始使用产品的新用户的参与情况,从而评估产品迭代或运营策略调整的得失。
2.初始行为和后续行为选择相同的,期待用户重复触发的事件。这种留存用于分析忠实用户的使用模式。
4 添加过滤条件

系统支持对初始行为或后续行为添加过滤条件(事件的细分维度)。比如,我们想分析广东地区的用户的留存情况,那么可以定义初始行为是“浏览页面”,同时添加筛选条件“省份匹配广东”,后续行为是也是“浏览页面”,即可满足分析需求。
5 留存观察粒度及自定义观察日期

设置用于观察留存率的时间粒度,支持天、周、月,可以根据业务需求分析出日留存、周留存、月留存。可根据需求选择第N日留存和N日内留存。
第N日留存指:距离初始行为第N天当天,出现后续行为的留存情况。
N日内留存指:发生初始行为开始,至第N日结束为止,这一时间段内出现后续行为的留存情况。
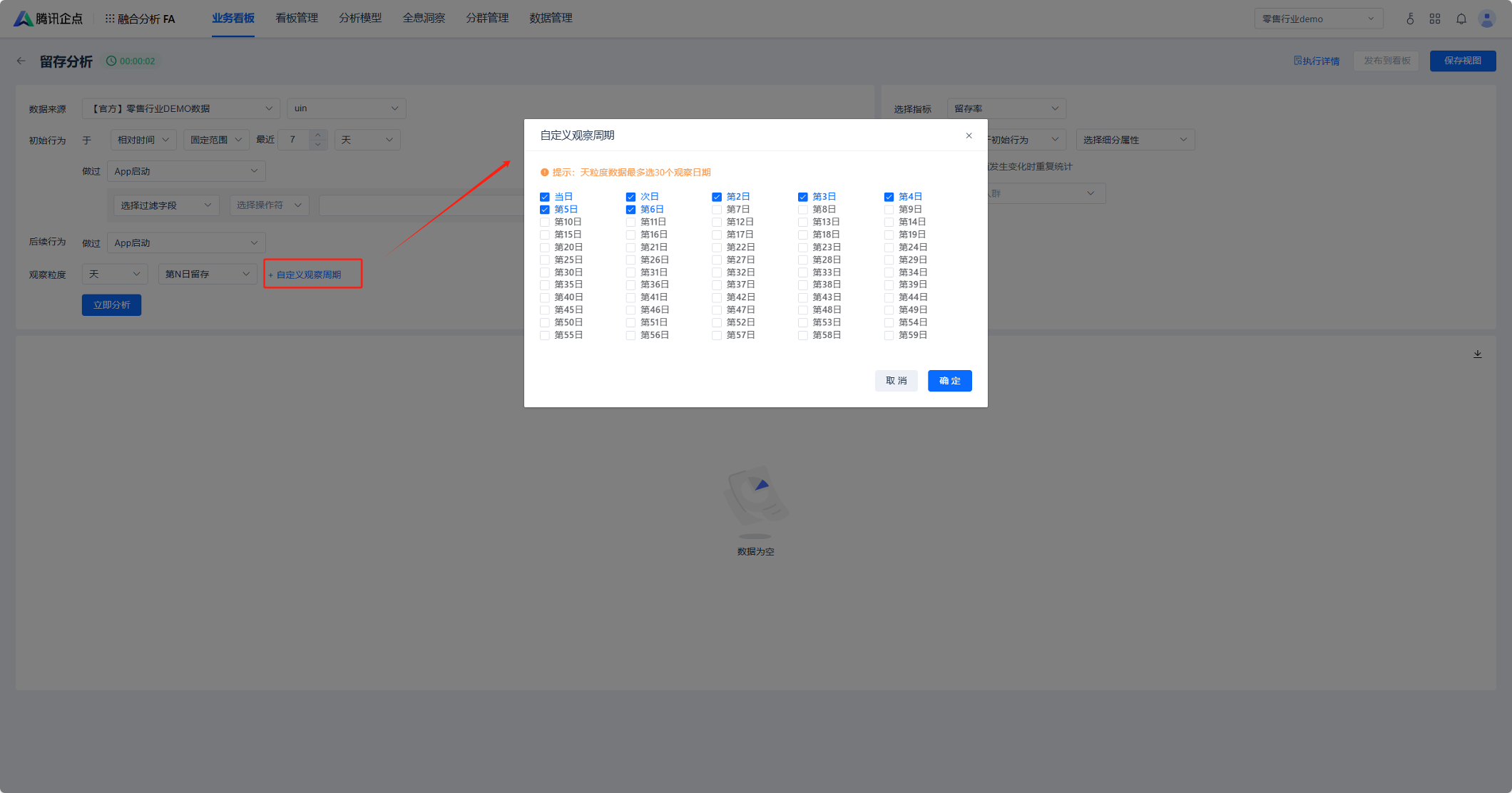
支持自定义选择N日/周/月观察日期,进行留存分析。
天粒度数据最多支持30个观察日期
周粒度数据最多支持8个观察日期
月粒度数据最多支持6个观察日期
第x天定义:指后续行为的触发时间距离初始行为的触发时间的天数。
6 指标选择
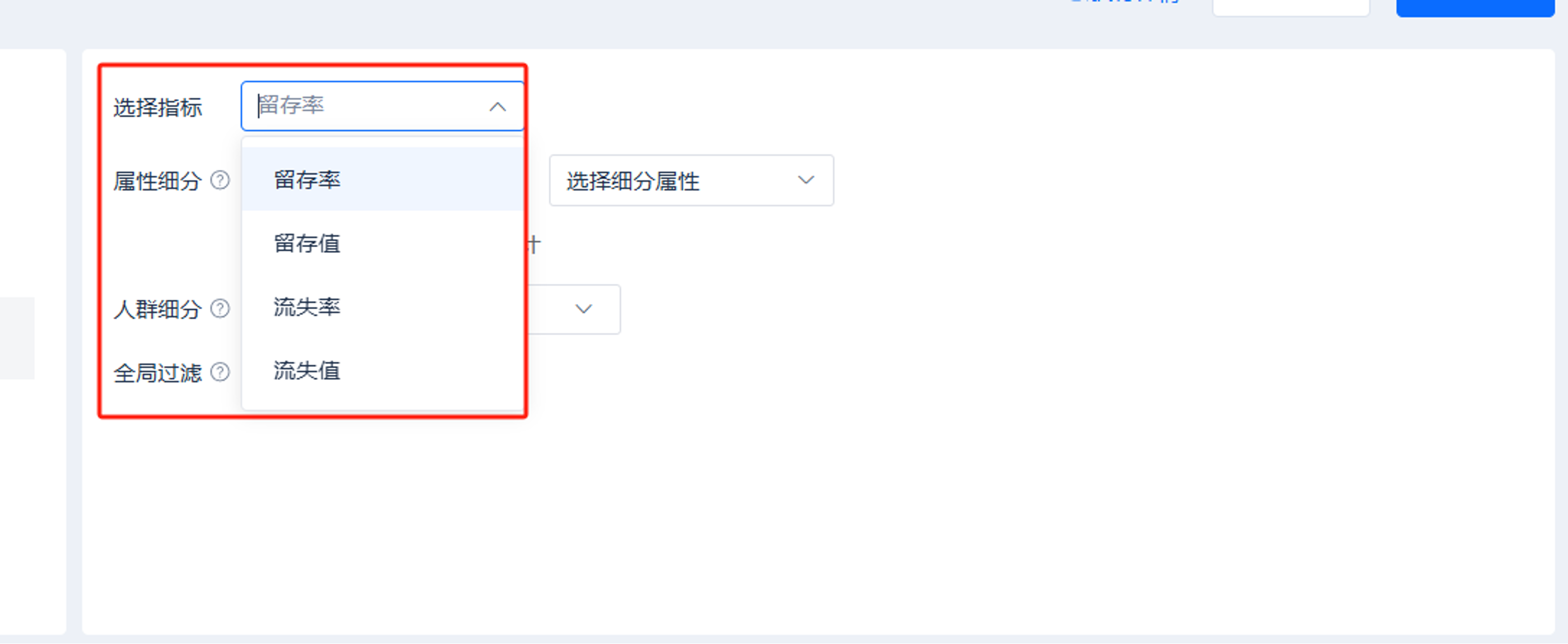
支持结果按留存率、留存值、流失率或流失值呈现。
假设触发初始行为的人群为A,四个指标的定义如下:
【留存率】A中触发了后续行为的人数/A的人数
【留存值】A中触发了后续行为的人数
【流失率】A中未触发后续行为的人数/ A的人数
【流失值】A中未触发后续行为的人数
7 设置图表的细分维度
系统支持业务根据用户细分维度、用户人群来绘制留存图表,增加图表洞察维度。比如可根据省份维度,来查看各省份注册用户,完成订单支付的留存情况。

8 分析图表及时间区间
 系统默认通过曲线图的方式来呈现留存情况,展示留存趋势变化。
系统默认通过曲线图的方式来呈现留存情况,展示留存趋势变化。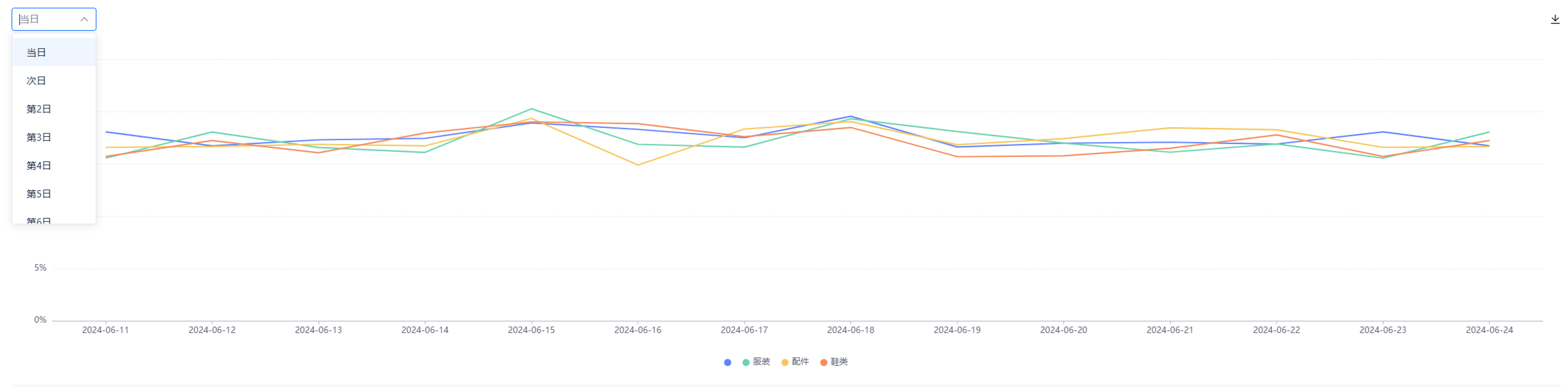 当选择了属性细分,则展示第X天的留存趋势变化。
当选择了属性细分,则展示第X天的留存趋势变化。
9 留存表格
提供另一种更全局的留存视图,后期在添加看板时,也可选择添加图表还是表格。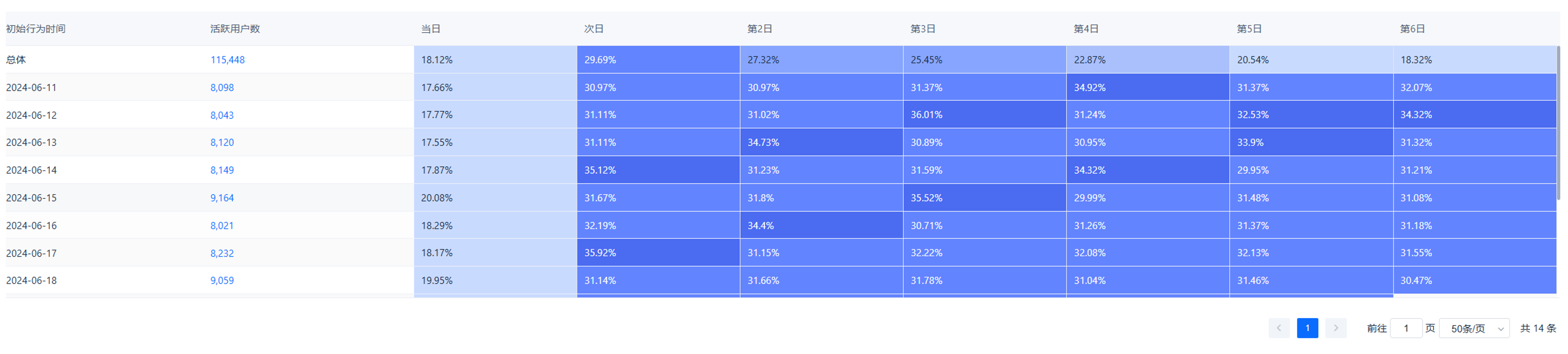 留存表格默认按照初始行为日期分组。每行的第一列代表了初始行为“日期/日期区间”(根据选择的观察粒度来划分);第二列是在该“日期/日期区间”触发了初始行为的总人数(独立用户数);后面各列,分别是在相应时间后,触发后续行为的用户数占初始行为人数的百分比。
留存表格默认按照初始行为日期分组。每行的第一列代表了初始行为“日期/日期区间”(根据选择的观察粒度来划分);第二列是在该“日期/日期区间”触发了初始行为的总人数(独立用户数);后面各列,分别是在相应时间后,触发后续行为的用户数占初始行为人数的百分比。
10 人群包导出

支持导出任意时间段的留存用户作为人群包,实现针对留存用户进行更进一步的探索分析。
11 留存分析的计算说明
留存分析中展示的数字代表独立用户数。表示在选定时间范围内进行了初始行为的用户,有多少人在随后的第n天/周/月进行了后续行为。
假设定义的初始行为是A事件,后续行为是B事件。留存观察粒度设置为:天;图表时间选择相对时间,最近7天;假设今天是2019年5月8日,那么,时间段为2019年5月1日到2019年5月8日,注意这个时间范围是事件A发生的时间范围,事件B发生的时间范围是2019年5月1日到5月15日(5月8日加上7天)。
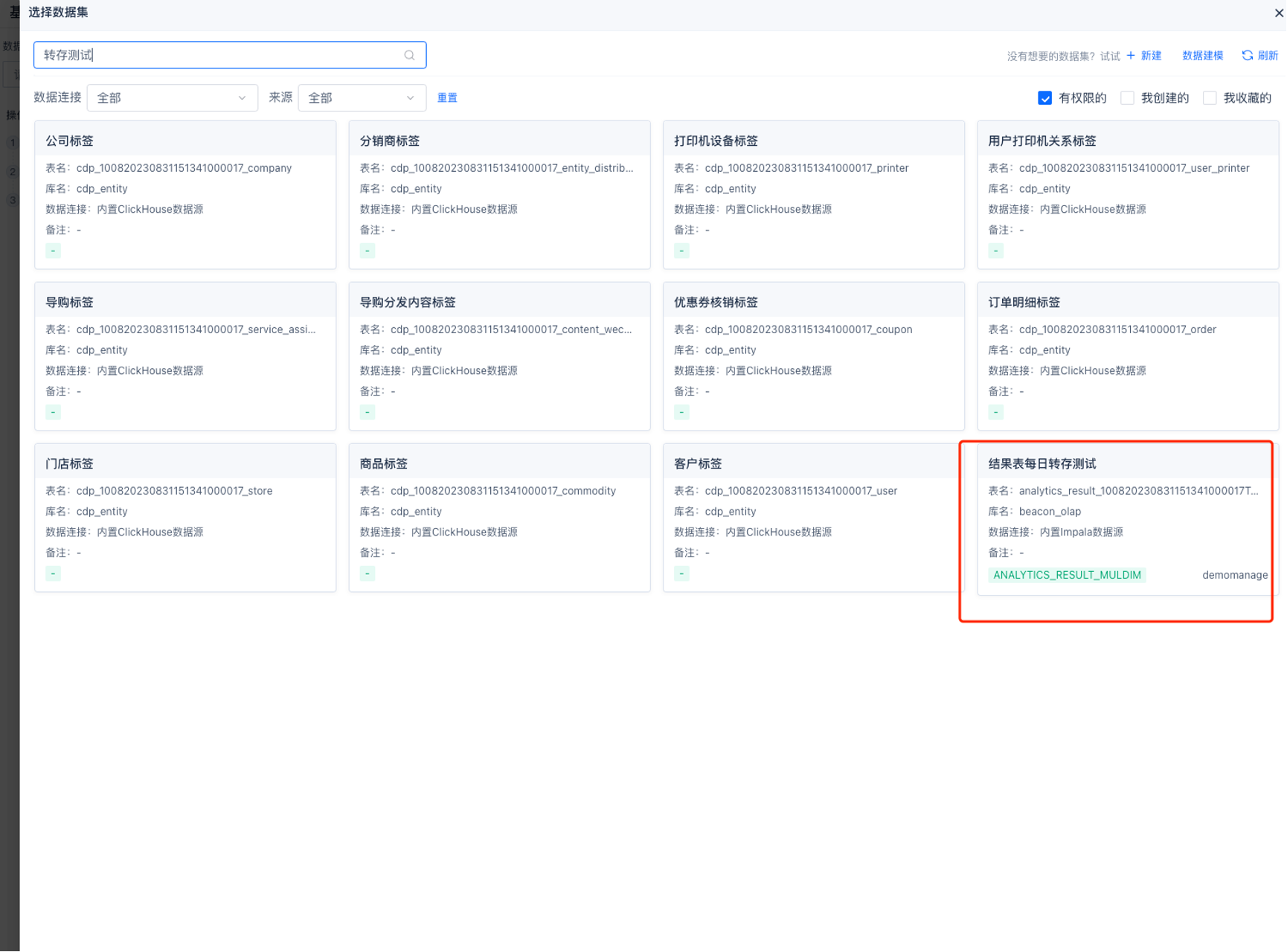
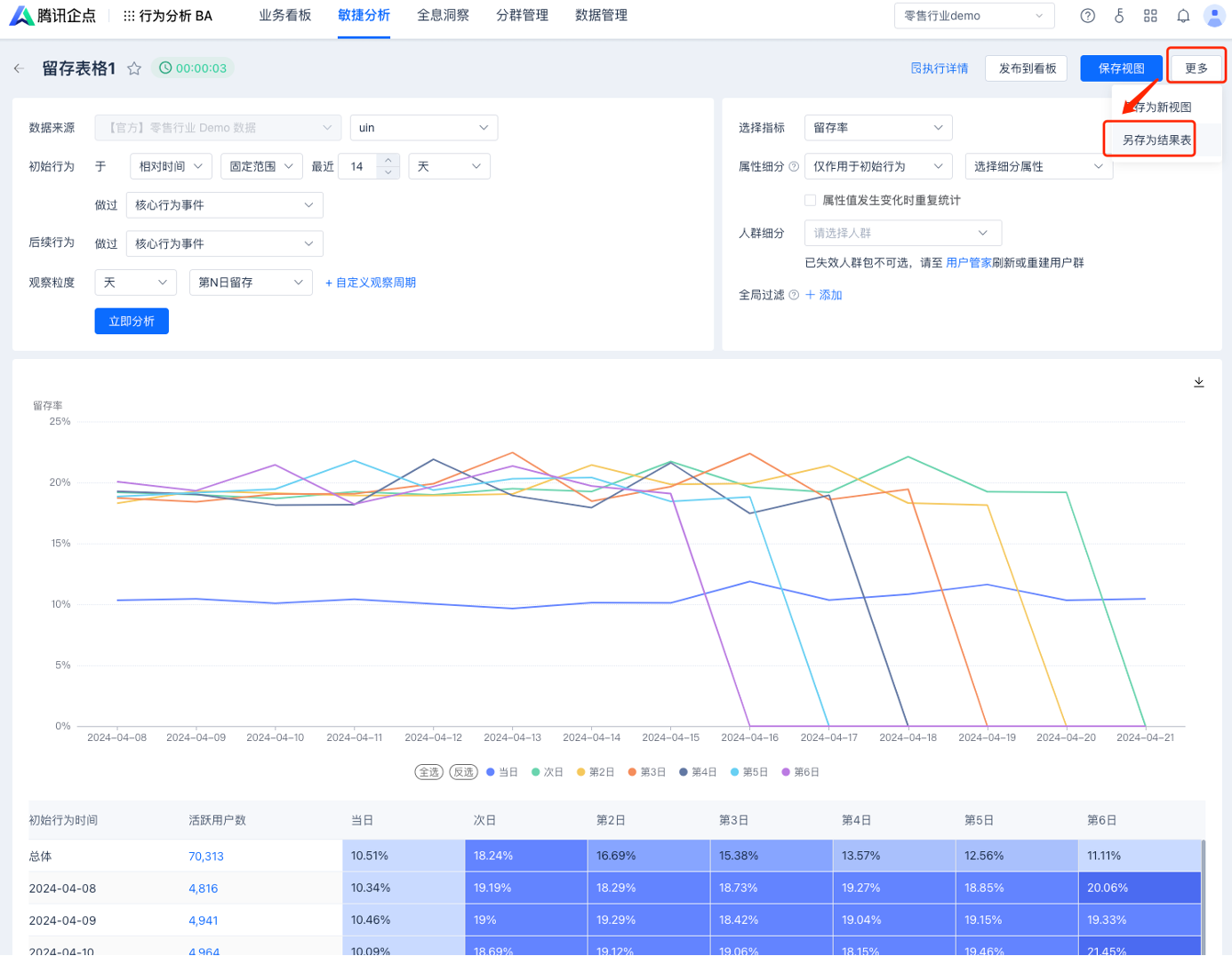
12 另存为结果表
支持每日自动根据配置的模型信息计算出结果数据,并将数据同步至普通表数据集中。配置过程如下:
1.有结果数据且已保存的分析模型,可在右上角更多中启用此功能。
2.在模型结果环节,在此确认查询口径以及下方的结果表数据预览。留存率将从百分数格式改为四位小数格式(超出部分四舍五入)。

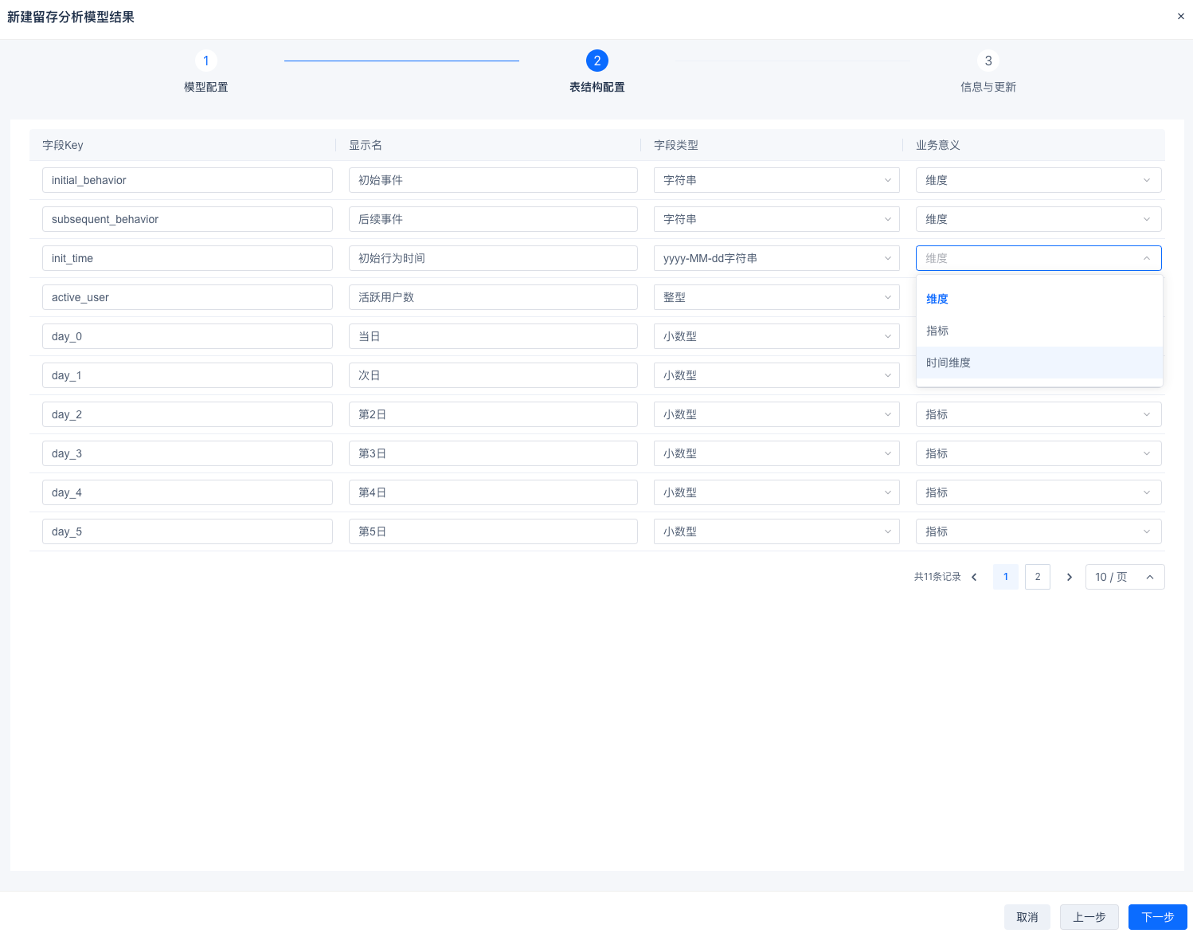
3.点击下一步,确认表结构(字段)配置信息,对于从已保存的模型中生成的结果表,系统将自动读取模型中配置的字段别名作为字段显示名,并读取默认字段类型。如果此环节系统赋予的字段类型不符合您后续的分析诉求(尤其是时间维度),请在此环节进行更改。
4.点击下一步,进入最终的信息与更新设置环节。基础信息中,数据集名称代表了未来在数据管家中列表页查看到的名称,数据表名称则代表了未来使用 SQL 查询这张结果表时的唯一表名。

更新设置中,手动更新代表仅希望将当前的数据同步至数据集中,后续无需更新。而周期性更新则代表希望系统在设置的频率下自动查询最新的数据,例如每天、每周或每月。频率中的具体执行时间推荐凌晨01:00-07:00,避免挤占日常分析、查询、使用产品的计算资源。
更新有效期:默认为180天,即产品将在180后自动停止更新。可修改为7天-永久的有效期,除长期、确定的核心指标内容,建议最长使用365天的有效期,以避免大量历史任务积累,影响平台性能。
数据覆盖策略:周期性更新任务将有多次更新,因此涉及多次更新中『同一维度的同一指标结果值不同』的场景,需要指定更新策略。比如模型配置为每次查询最近7日数据,经过100天后,第101日将查询到94-100日这七天的数据。除了100日的数据是本次新增的,94-99这六天都已经有了历史数据。如覆盖策略配置为『覆盖相同维度数据』,则最终结果为第100天数据新增,94-99日数据更新为最新查询到的结果,1-93日数据保持不变。
如果设置为『替换全部数据』,则1-99日的历史数据全部都会被删除,再使用最新查询到的94-100日这七天的数据替换新增,最终只有库中只会有这7天的数据。
如果设置『仅新增数据』,则不会将新增数据与历史数据进行比对,总是将新数据进行插入,可能出现重复数据。
如果担心覆盖策略较为复杂,影响同步结果。建议模型配置时将时间设置的范围与更新频率保持完全一致,例如每日更新的数据,模型里查询的数据时间范围只查询最近1天,这样将不存在维度数据重合的问题,数据覆盖策略选择覆盖相同维度或仅新增数据均可。
5.在系统进行可视化组件配置时,选择数据集时搜索自己设置的数据集名称,即可使用这张结果表。